스포츠 데이터를 다뤄 온 입장에서 말씀드리면, 득점이나 타점처럼 결과만 남는 전통 기록으로는 선수의 실력을 끝까지 설명하기 어렵습니다. 결과 지표는 이미 발생한 장면의 요약이지만, 현대 퍼포먼스 분석은 그 결과가 어떤 프로세스에서 나왔는지를 더 중요하게 봅니다. 그래서 현장에서는 xG, xwOBA, 스크린 어시스트 같은 과정 중심 메트릭을 함께 해석합니다. 이런 지표는 슈팅 선택, 타구 질, 오프볼 기여, 스페이싱 창출처럼 박스스코어 밖의 가치를 계량화해 일시적 운과 반복 가능한 퍼포먼스를 분리해 줍니다. 결국 지속 가능한 선수란, 한 경기의 결과보다 재현 가능한 과정 데이터를 꾸준히 남기는 선수입니다.
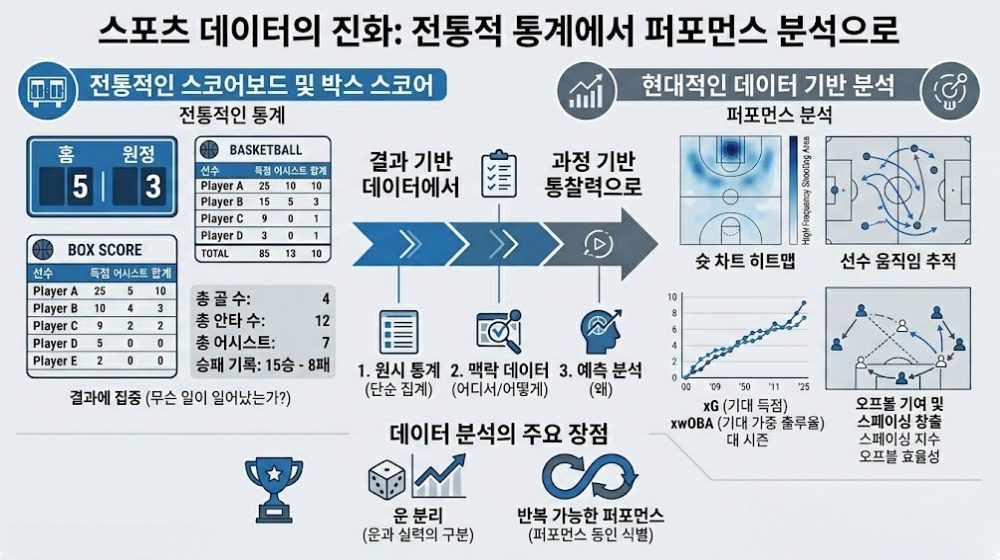
앞서 과정 데이터의 중요성을 말씀드렸다면, 축구에서는 그 관점을 한층 더 동적으로 봐야 합니다. 이 종목은 한 장면이 고정된 뒤 평가되는 게임이 아니라, 점유·전진·압박·전환이 연속적으로 이어지는 흐름의 스포츠이기 때문입니다. 그래서 단순 패스 성공률보다 라인브레이킹 패스, 전진 운반, 압박 빈도와 방향, 볼 리시브 인 스페이스 같은 지표가 더 많은 설명력을 가집니다. 중요한 점은 온 더 볼만이 아닙니다. 오프 더 볼 움직임 역시 수비 라인 사이 침투, 압박 각도 형성, 패스 길 차단, 간격 유지로 데이터화됩니다. 실제 프로 구단은 이벤트 데이터에 트래킹 데이터와 영상을 동기화해 상대 분석, 경기 후 리뷰, 훈련 설계까지 연결하며, 이 과정에서 선수의 전술 수행력과 재현 가능성을 함께 판독합니다.

그중 가장 먼저 이해하셔야 할 지표가 xG입니다. xG는 한 슈팅이 득점으로 이어질 확률을 뜻하며, 슈팅 위치와 각도, 바디 파트, 패스 유형 등 과거 유사 장면의 데이터를 바탕으로 확률 모델이 산출합니다. 다시 말해 골이 들어갔는지만 보는 수치가 아니라, 어떤 찬스였는지를 평가하는 기준입니다. 그래서 실제 득점이 xG를 단기간 크게 웃돌면 좋은 결정력에 더해 행운이 작용했을 가능성을 함께 봐야 하고, 긴 표본에서 꾸준히 xG를 상회한다면 마무리 능력이 검증된 공격수로 해석할 수 있습니다.
xG가 슈팅의 질을 본다면, 창조성 평가는 키패스와 xA에서 더 분명해집니다. 키패스는 동료의 슈팅으로 직접 이어진 마지막 패스이고, xA는 그 패스가 도움이 될 확률을 추정한 값입니다. 따라서 어시스트는 결과를 세지만, xA는 패스 자체가 만든 위험도를 평가합니다. 이 차이 때문에 수신자가 마무리를 놓쳐도 패서의 능력은 사라지지 않습니다. 실제로 높은 xA를 꾸준히 기록하는 선수는 동료의 결정력과 별개로, 지속적인 찬스 생산력을 증명하는 사례로 해석할 수 있습니다.
야구는 모든 투구와 타구가 사건 단위로 끊겨 기록되는 턴제 스포츠입니다. 그래서 세이버메트릭스는 다른 종목보다 더 정교하게 발전할 수 있었습니다. 빌 제임스가 말한 세이버메트릭스의 본질은 야구를 객관적으로 이해하려는 시도이며, 타율이나 승수처럼 겉으로 보이는 결과보다 실제로 득점과 승리에 얼마나 기여했는지를 묻는 데 있습니다. 이 관점에서 현대 구단은 출루와 장타, 수비와 주루를 따로 보지 않고 RC, wOBA, WAR처럼 팀 가치로 환산해 해석합니다. 결국 세이버메트릭스는 잘했는가보다, 팀을 얼마나 더 이기게 했는가를 측정하는 언어에 가깝습니다.

세이버메트릭스의 언어로 풀면, WAR은 서로 다른 재능을 하나의 승리 단위로 번역한 값입니다. 타격이 몇 점을 만들었는지, 주루가 몇 점을 더했는지, 수비가 몇 점을 막았는지를 먼저 득점 가치로 환산한 뒤, 여기에 포지션 보정과 대체 선수 기준을 더해 최종적으로 몇 승의 차이를 만들었는지 계산합니다. 여기서 대체 선수란 부상이나 공백이 생겼을 때 비교적 쉽게 채울 수 있는 벤치 자원이나 마이너리거 수준을 뜻합니다. 또한 유격수와 1루수는 평균 수비력이라도 요구 난도와 희소성이 다르기 때문에, 포지션별 보정값이 반드시 들어가야 같은 저울 위에서 공정하게 비교할 수 있습니다.
WAR이 투수의 총가치를 묶어 보여준다면, FIP는 그 안에서 투수 본연의 투구 품질만 따로 떼어 보는 지표입니다. 핵심은 단순합니다. 수비의 범위나 타구 운에 크게 흔들리는 인플레이 결과 대신, 투수가 비교적 직접 통제하는 홈런과 볼넷, 탈삼진을 중심으로 실점 수준을 추정하는 것입니다. 그래서 ERA가 수비 지원, BABIP, 잔루 처리 같은 외부 변수에 민감한 반면, FIP는 과정의 질을 더 선명하게 드러냅니다. 결국 미래 성적을 볼 때는 이미 벌어진 실점보다, 어떤 방식으로 타자를 상대했는지를 보여주는 FIP가 더 유용한 기준이 됩니다.
현대 농구에서 점수를 많이 넣는다는 사실만으로는 선수를 충분히 설명할 수 없습니다. 더 중요한 것은 한 번의 공격 소유권을 얼마나 적게 낭비하며 득점으로 바꾸느냐입니다. 그래서 NBA 분석에서는 단순 득점보다 Offensive Rating, eFG%, TS%처럼 포제션당 생산성과 슈팅 효율을 먼저 봅니다. 여기에 현대 농구의 페이스와 스페이싱 개념이 결합됩니다. 공격 템포가 빨라져도 공간 창출이 받쳐주지 않으면 효율은 떨어지며, 반대로 넓은 간격과 빠른 볼 무브는 같은 소유권에서 더 높은 기대 득점을 만듭니다. 결국 효율성은 기록 장식이 아니라 승률을 만드는 구조입니다.
PER는 존 홀린저가 만든 1분당 생산성 지표로, 득점과 리바운드, 어시스트, 스틸, 블록 같은 긍정 기록에는 가중치를 더하고, 놓친 슛과 턴오버, 파울 같은 부정 기록은 차감한 뒤 출전 시간 기준으로 환산하고 팀 페이스까지 보정해 계산합니다. 이렇게 서로 다른 박스스코어 기여를 한 숫자로 묶어 선수 간 직관적인 비교와 순위화가 쉬운 점이 장점입니다. 다만 PER는 통계로 잡히는 생산성에는 강하지만 수비 위치선정이나 오프 더 볼 영향처럼 비가시적 기여는 충분히 담지 못합니다.
PER가 생산성을 넓게 묶어 본다면, TS%는 그중 득점 효율만 정밀하게 분리해 보여주는 지표입니다. 기존 야투율은 2점슛과 3점슛을 같은 한 번의 성공으로 처리하고, 자유투로 만든 득점 가치도 충분히 반영하지 못해 슈터의 실제 공격력을 왜곡합니다. 반면 TS%는 총득점을 슈팅 시도와 자유투 시도의 가중 합으로 나눠 계산하며, 여기서 0.44는 자유투가 실제 공격 소유권을 얼마나 차지하는지 근사한 값입니다. 따라서 진정한 슈터의 가치는 단순 야투율이 아니라, 3점과 자유투까지 포함해 전체 득점 효율을 얼마나 높게 유지하느냐로 판단하셔야 합니다.
이제 중요한 것은 숫자를 읽는 데서 끝나지 않고, 숫자가 무엇을 증명하는지까지 해석하는 일입니다. 실무 분석가들은 대체로 세 단계로 사고를 확장합니다. 첫째, 지표의 정의와 표본을 확인합니다. 값이 무엇을 계산한 결과인지, 경기 수가 충분한지 먼저 점검해야 우연을 실력으로 오인하지 않습니다. 둘째, 맥락을 붙입니다. 포지션, 전술 역할, 팀 페이스, 상대 수준을 함께 보아야 같은 수치도 의미가 달라집니다. 셋째, 영상과 보조 데이터를 교차 검증합니다. 결국 정확한 해석은 숫자 하나가 아니라 정의, 맥락, 검증의 순서에서 나옵니다.
실전 해석의 출발점은 숫자의 크기보다 숫자의 성격을 구분하는 일입니다. 누적 데이터는 득점, 안타, 리바운드처럼 많이 뛰고 많이 맡을수록 쌓이는 값이라 역할과 내구성을 보여주지만, 그것만으로 기량을 단정하긴 어렵습니다. 반면 비율 데이터는 90분당, 포제션당, 타석당처럼 기회 대비 생산성을 환산해 출전 시간 차이를 보정합니다. 따라서 평가는 누적치로 볼륨을 확인하고, 비율치로 효율과 순수 실력을 검증하는 순서로 보셔야 합니다.
다음 단계에서는 숫자를 그대로 비교하지 말고, 환경을 먼저 표준화해 보셔야 합니다. 같은 0.900 OPS라도 타고투저 시즌과 투고타저 시즌의 의미는 다르기 때문입니다. 그래서 OPS+와 wRC+는 해당 시즌과 리그, 구장 맥락을 반영한 뒤 평균을 100으로 맞춥니다. 이때 120은 리그 평균보다 20퍼센트 우수하고, 80은 20퍼센트 낮다는 뜻입니다. 이런 조정 지표를 쓰면 절대 수치보다 그 선수가 당시 환경에서 얼마나 압도적이었는지를 더 공정하게 판단할 수 있습니다. 특히 시대와 리그가 달라도 비교 가능성이 높아진다는 점이 핵심입니다.
같은 OPS라도 시즌 득점 환경과 리그 수준이 다르면 의미는 달라집니다. OPS+와 wRC+는 평균을 100으로 표준화해, 선수가 당시 환경에서 얼마나 우수했는지를 더 공정하게 보여줍니다.
신뢰도 증폭 포인트
AVG = 100
120이면 리그 평균 대비 20% 우수, 80이면 20% 낮음을 뜻합니다. 절대 수치보다 맥락 보정 후 우위를 판단하는 데 강합니다.
Raw Stat Focus
0.900 OPS
원시 수치만 보면 모두 비슷해 보여도, 시즌 환경이 다르면 실제 체감 가치는 달라집니다.
Adjusted Stat Focus
OPS+ / wRC+
리그 평균과 구장, 득점 환경을 반영해 같은 숫자의 무게를 다시 계산합니다.
Business / Trust Value
비교 신뢰도 상승
시대와 리그가 달라도 비교 가능성을 높여 콘텐츠 설득력과 전문성을 강화합니다.
선수
Player A
타고투저 시즌
시즌 환경
득점 친화적 리그 / 공격 지표 전반 상승
원시 OPS
.900조정 OPS+
108
조정 wRC+
110
맥락 해석
겉보기 OPS는 높지만, 득점 환경을 감안하면 우위가 다소 축소됩니다.
평가 변화
보통 이상
선수
Player B
투고타저 시즌
시즌 환경
저득점 리그 / 타격 생산성 확보 어려움
원시 OPS
.900조정 OPS+
129
조정 wRC+
132
맥락 해석
같은 OPS라도 저득점 환경에서는 상대적 지배력이 훨씬 크게 평가됩니다.
평가 변화
가치 상승
선수
Player C
중립 환경 + 구장 불리
시즌 환경
홈 구장 타자 친화도 낮음 / 보정 효과 발생
원시 OPS
.874조정 OPS+
124
조정 wRC+
126
맥락 해석
원시 기록은 다소 낮아 보여도, 구장 보정 후에는 상위 타자로 재평가될 수 있습니다.
평가 변화
재평가
선수
Player D
타자 친화 구장
시즌 환경
원시 기록 부풀림 가능성 존재
원시 OPS
.921조정 OPS+
103
조정 wRC+
101
맥락 해석
겉보기 수치는 강하지만, 구장과 리그 환경을 빼면 평균 근처로 수렴합니다.
평가 변화
과대평가 경계
OPS+ / wRC+에서 100은 평균, 120 이상은 확실한 우위, 140 이상은 리그 지배권 수준으로 해석하면 이해가 쉽습니다.
세 번째 단계에서는 높은 수치보다 먼저 그 수치가 몇 번의 기회에서 나왔는지를 보셔야 합니다. 10번의 슈팅에서 나온 성공률과 200번의 슈팅에서 나온 성공률은 같은 값이어도 신뢰도가 다릅니다. 표본이 작을수록 우연한 변동이 크게 섞이므로, 분석가는 지표별 최소 기회 수를 정하고 이전 데이터와 리그 평균을 함께 보며 평균 회귀를 감안해 해석합니다. 중요한 점은 통계가 어느 한순간 갑자기 안정화되는 것이 아니라 점진적으로 신뢰도를 얻는다는 사실입니다. 표본이 부족한데도 복잡한 결론을 서둘러 내리면 신호보다 잡음을 학습하는 과적합에 빠지기 쉽습니다.
마지막으로 기억하셔야 할 점은, 절대적으로 가장 정확한 지표는 없다는 사실입니다. 실제 현업에서도 단일 수치만으로 선수를 확정하지 않으며, 데이터는 평가 목적에 맞춰 조합해 사용합니다. 초기 스크리닝 단계라면 WAR처럼 총가치를 빠르게 보여주는 지표가 유용하고, 타자 영입 판단에서는 리그와 구장 효과까지 보정하는 wRC+가 우선순위가 될 수 있습니다. 반대로 축구 영입에서는 단순 득점보다 xG와 역할별 이벤트 데이터를 함께 보며 미래 재현성을 판단하는 편이 더 합리적입니다. 예를 들어 우승 경쟁 팀은 즉시 전력 지표를, 예산 제약이 큰 팀은 성능뿐 아니라 이적 시점과 재무 균형까지 함께 봐야 합니다. 결국 좋은 분석은 최고의 숫자를 찾는 일이 아니라, 목표에 맞는 숫자를 올바른 순서로 고르는 일입니다.
절대적으로 가장 정확한 지표는 없습니다. 실제 평가는 목적에 따라 조합이 달라지며, 초기 스크리닝, 즉시 전력 판단, 미래 재현성 검토, 예산 통제 같은 상황마다 우선순위가 달라집니다. 결국 좋은 분석은 최고의 숫자 하나를 찾는 일이 아니라, 목표에 맞는 숫자를 올바른 순서로 고르는 일입니다.
Decision Principle
Fit > Best
상황에 맞는 지표 조합이 단일 최고 지표보다 더 빠르고 정확한 판단을 만듭니다.
초기 스크리닝
WAR 중심
총가치를 빠르게 훑어야 할 때는 압축력이 높은 지표가 유리합니다.
공격 생산성 판단
wRC+ 우선
리그와 구장 보정이 필요한 영입 판단에서는 조정 지표 우선순위가 높습니다.
미래 재현성 검토
xG + 이벤트 데이터
현재 결과보다 과정과 역할 데이터를 함께 봐야 다음 시즌 예측력이 올라갑니다.
종목
판단 상황
우선 추천 지표
함께 볼 보조 지표
활용 포인트
종목
Soccer
미래 재현성 / 영입 검토
판단 상황
단순 득점 수치보다 다음 시즌에도 반복될 퍼포먼스를 찾고 싶을 때
우선 추천 지표
함께 볼 보조 지표
활용 포인트
종목
Baseball
타자 영입 / 공격 생산성
판단 상황
리그와 구장 차이를 제거하고 실제 공격 기여를 비교해야 할 때
우선 추천 지표
함께 볼 보조 지표
활용 포인트
종목
Basketball
즉시 전력 / 팀 적합성
판단 상황
우승 경쟁 팀처럼 지금 당장 효율과 역할 적합성을 판단해야 할 때
우선 추천 지표
함께 볼 보조 지표
활용 포인트
종목
Cross-Sport
초기 스크리닝 / 후보 압축
판단 상황
많은 후보를 짧은 시간 안에 추려야 하고, 총가치부터 빠르게 확인해야 할 때
우선 추천 지표
함께 볼 보조 지표
활용 포인트
종목
Budget-Constrained Team
예산 제약 / 타이밍 판단
판단 상황
성능뿐 아니라 이적 시점, 비용 구조, 재무 균형까지 함께 검토해야 할 때
우선 추천 지표
함께 볼 보조 지표
활용 포인트
추천 방식은 “종목 → 판단 상황 → 우선 지표 → 보조 지표” 순서로 읽히게 설계했습니다. 그래서 사용자가 어떤 숫자를 먼저 보고, 무엇을 뒤에 붙여야 하는지 빠르게 결정할 수 있습니다.
수비수 평가는 태클 성공률 하나로는 부족합니다. 현대 분석에서는 먼저 가로채기와 전진 패스 차단으로 패스 라인을 읽는 능력을 보고, 다음으로 상대 점유 시간을 기준으로 보정한 압박 강도와 챌린지 인텐시티로 개입 빈도의 질을 봅니다. 여기에 공중 경합 승률, 박스 안 블록, 클리어링을 더하면 최종 저지 능력까지 확인할 수 있습니다. 특히 위험 지역에서 나온 수비 행동의 가치를 따로 계산하는 모델은 포지셔닝과 판단의 질까지 드러냅니다. 실무용 추천 세트는 가로채기, 패스 차단, 점유 보정 압박, 공중볼 승률, 박스 블록, 수비 가치 모델 순으로 보시면 가장 안정적입니다.
영입 시장에서 가성비 선수를 찾는다는 것은 단순히 몸값이 낮은 선수를 고르는 일이 아니라, 시장 가치보다 경기 기여가 앞서는 선수를 구조적으로 선별하는 일입니다. 현대 머니볼 방식은 먼저 팀의 게임 모델과 포지션 역할을 정의한 뒤, 출전 시간 하한선과 연령, 리그 수준, 역할별 핵심 지표를 필터링해 후보군을 압축합니다. 이후 유사 선수 검색과 지표 가중치 조정으로 스타일 적합도를 비교하고, 최종 단계에서 영상 클립과 플레이리스트로 수치가 전술 맥락에서도 반복되는지 검증합니다. 실제 스카우팅 워크플로우 역시 데이터 선별 뒤 영상 확인으로 리스크를 줄이며 숏리스트를 정교화하는 구조를 취합니다.
숫자는 거짓말을 하지 않지만, 해석은 얼마든지 거짓말을 할 수 있습니다. 데이터는 경기의 흔적을 정교하게 남기지만, 선수의 멘탈리티나 리더십, 압박 상황에서의 책임감처럼 팀 성과를 바꾸는 무형의 가치까지 완전하게 포착하지는 못합니다. 더 위험한 함정은 확증 편향입니다. 기존 기대를 지지하는 증거만 더 모으고 강조하기 시작하면, 데이터는 분석 도구가 아니라 결론을 합리화하는 장식이 됩니다. 그래서 좋은 분석가는 마음에 드는 수치만 고르지 않고, 반대 사례와 영상, 역할 맥락까지 함께 대조해 결론을 늦게 내립니다. 결국 데이터는 답안지가 아니라, 검증을 요구하는 단서에 가깝습니다.
가장 먼저 보셔야 할 것은 결과의 크기가 아니라, 그 결과가 어떤 과정에서 나왔는지입니다. 실제 득점이 xG를 단기간 크게 웃돌면 일시적 호조일 수는 있어도, 우선은 오버퍼포먼스로 해석하는 편이 안전합니다. xG는 찬스 질의 기대값이므로 표본이 작을수록 골 수는 운의 영향을 크게 받습니다. 반대로 많은 슈팅에서도 득점이 꾸준히 xG를 상회하고, xGOT처럼 유효슈팅의 마무리 질까지 함께 높다면 실력 향상으로 볼 근거가 생깁니다. 핵심은 폭발적인 몇 경기보다, 큰 표본에서 과정 지표가 반복적으로 재현되는지 확인하는 일입니다.
결국 데이터 분석의 최종 목적은 숫자를 더 많이 아는 데 있지 않습니다. 그 목적은 경기 안에서 무엇이 반복되고, 무엇이 우연이며, 무엇이 진짜 실력인지를 더 정밀하게 읽어내는 데 있습니다. 데이터는 분명 탁월한 지도입니다. 선수의 움직임을 구조로 바꾸고, 보이지 않던 기여를 언어로 번역하며, 감정에 기대던 판단을 검증 가능한 해석으로 끌어올려 줍니다. 그러나 지도만으로는 경기의 온도를 완전히 이해할 수 없습니다. 실제 장면의 맥락, 흐름의 변화, 압박 순간의 선택, 팀 전체의 리듬은 결국 경기를 직접 보고 읽는 직관과 함께 놓일 때 비로소 선명해집니다.
좋은 분석은 데이터와 영상, 그리고 현장의 감각이 서로를 부정하지 않고 보완할 때 완성됩니다. 그런 점에서 스탯을 공부한다는 것은 숫자를 외우는 일이 아니라, 경기를 더 깊고 넓게 이해하는 시야를 갖추는 일에 가깝습니다. 그리고 바로 그 순간부터 스포츠는 단순한 결과의 소비가 아니라, 읽을수록 더 흥미로워지는 해석의 세계가 됩니다.